Data Analysis Foundation 数据分析基础
Iterative Algorithm, Another View 迭代算法,另一种观点
给定一个有 k 个节点的 CFG,迭代算法会更新每个节点 n 的 OUT[n] 值。那么我就可以考虑把这些值定义为一个 k-tuple:
\[(OUT[n_1],OUT[n_2],...,OUT[n_k])\in (V_1\times V_2 \times ...\times V_k) = V^k\]则,我们的数据流分析迭代算法框架就可记为
迭代过程就被记为:
- $X_0 = (null, null, …, null)$
- $X_1 = (v_1^1,v_2^1,…,v_k^1) = F(X_0)$
- $X_2 = (v_1^2,v_2^2,…,v_k^2) = F(X_1)$
- …
- $X_i = (v_1^i,v_2^i,…,v_k^i) = F(X_{i-1})$
- $X_{i+1} = (v_1^i,v_2^i,…,v_k^i) = F(X_{i})$
- 此时我们发现$X_i =X_{i+1}$,意味着$X_i$就是$F$的一个不动点。
在这个框架下,我们就有一些想知道的问题:
- 算法是否确保一定能停止/达到不动点?会不会总是有一个解答?
- 如果能到达不动点,那么是不是只有一个不动点?如果有多个不动点,我们的结果是最优的吗?
- 什么时候我们会能得到不动点?
为了回答这个问题,我们需要先回顾一些数学。
Partial Order 部分定理
所谓偏序集合(poset),就是一个由集合 $P$ 和偏序关系$\sqsubseteq$所组成$(P, \sqsubseteq)$对。这个对满足以下三个条件:
- Reflexivity 自反性:x $\sqsubseteq$ x
- Antisymmetry 反对称性:x $\sqsubseteq$ y, y $\sqsubseteq$ x, 则 x = y
- Transitivity 传递性:x $\sqsubseteq$ y, y $\sqsubseteq$ z, 则 x $\sqsubseteq$ z
- 例子:小于等于关系就是一个偏序关系,但小于关系不是偏序关系,它是全序关系。
偏序关系与全序关系的区别在于,全序关系可以让任意两个元素比较,而偏序关系不保证所有元素都能进行比较。
Upper and Lower Bounds 上界和下界
对于偏序集中的某子集 S 来说:
- 若存在元素 u 使得 S 的任意元素 x 有 x $\sqsubseteq$ u,那么我们说 u 是 S 的上界(Upper bound)。
- 同理,若存在元素 l 使得 S 的任意元素 x 有 l $\sqsubseteq$ x,那么我们说 l 是 S 的下界(Lower bound)。
然后我们衍生出最小上界和最大下界的概念:
- 在 S 的所有上界中,我们记最小上界(Least upper bound, lub)为$\sqcup S$,满足所有上界 u 对 lub 有: $\sqcup S \sqsubseteq u$
- 类似地我们也能定义出最大下界(Greatest lower bound, glb)为$\sqcap S$。
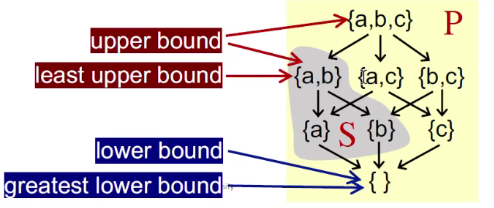
当 S 的元素个数只有两个{a, b}时,我们还可以有另一种记法:
- 最小上界:$a \sqcup b$, a join b
- 最大下界:$a \sqcap b$, a meet b
并不是每个偏序集都有 lub 和 glb,但是如果有,那么该 lub, glb 将是唯一的。(可假设存在多个,然后用自反性证明它们是同一个)
Lattice, Semilattice, Complete and Product Lattic 格子、半格子、完全格子和产品格子
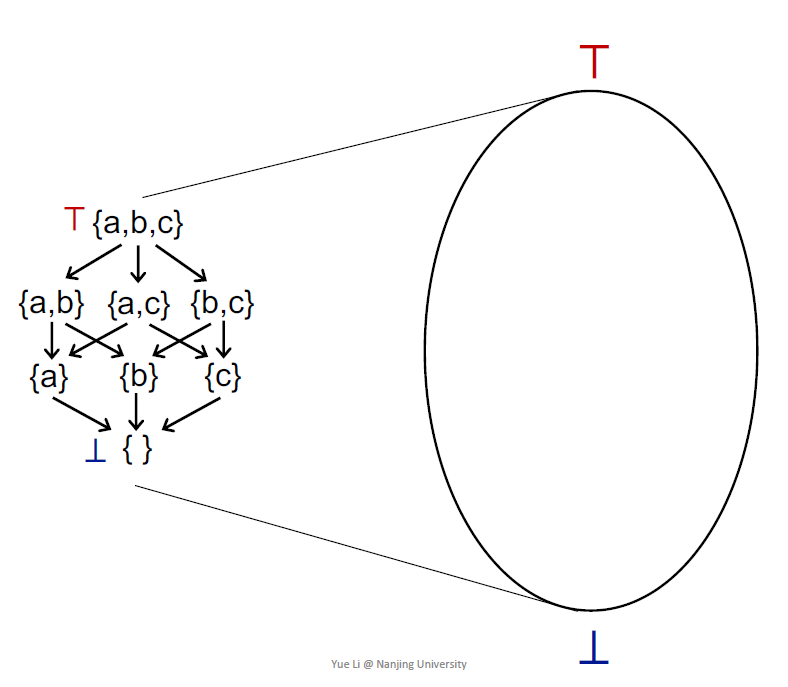
给定一个偏序集,如果任意元素 a, b 都有 lub和glb,那么这么偏序集就叫做 格(lattice)。
- 属于 lattice 的:小于等于关系,子集关系
- 不属于 lattice 的:子串关系
如果在此之上更加严格一些,任意集合都存在 lub 和 glb,那么我们说这个 lattice 为“全格(complete lattice)”
- 属于全格的:子集关系
- 不属于全格的:小于等于关系,因为全体正整数没有一个边界
每一个全格都存在着最大元素$\top$ (top)和最小元素$\bot$ (bottom),他们分别是整个集合的 lub 和 glb。
如果一个 lattice 是有穷的,那么它一定是一个全格。
然而,一个全格不一定是有穷的,例如[0, 1]之间的实数是无穷的,但是期间的小于等于关系可以使其成为全格。
另外还有 Product Lattice,多个 lattice 的笛卡尔积也能形成一个新的 lattice。
需要记住的是:
- product lattice 也是一个 lattice
- 如果 product lattice L是全格的积,那么 L 也是全格。
扩展阅读:如果偏序集任意两元素的上下界仅有其 lub 和 glb,那么称该偏序集为半格(Semilattice)
Data Flow Analysis Framework via Lattice 通过格子的数据流分析框架
一个数据流分析框架(D, L, F)由以下元素组成:
- D: 数据流的方向,前向还是后向
- L: 包含了数据值 V 和 meet, join 符号的格
- F: V -> V 的转移方程族
从而,数据流分析可以被视为在 lattice 的值上迭代地应用转移方程和 meet/join 操作符。

Monotonicity and Fixed Point Theorem 单调性和不动点定理
回看我们在上面提出的问题:迭代算法在什么条件下可以停机?我们在这里引入不动点定理:
Monotonicity 单调性:如果\sqsubseteq f(y)$],则说函数f: L -> L 是单调的。
FIxed Point Theorem 不动点定理:给定一个全格$(L,\sqsubseteq)$,如果
-
$f: L \rightarrow L$是单调的
-
$L$是有穷的
(也就是f单调有界+L全格)
那么
-
迭代$f^k(\bot)$可以得到最小不动点(least fixed point)。
-
迭代$f^k(\top)$可以得到最大不动点(greatest fixed point)。
证明:
根据$\bot$和f的定义,我们可以得到:$\bot \sqsubseteq f(\bot)$。
由于 L 是有限的,且 f 单调,根据鸽笼原理,必然存在一个 k 使得$\bot \sqsubseteq f(\bot) \sqsubseteq f^2(\bot)\sqsubseteq …\sqsubseteq f^k(\bot)\sqsubseteq f^{k+1}(\bot) $,且$f^k(\bot) = f^{k+1}(\bot)$。
假设我们有另一个任意不动点 x,由于 f 是单调的,因此$f(\bot) \sqsubseteq f(x), f^2(\bot) \sqsubseteq f^2(x),…,f^{Fix} = f^k(\bot)\sqsubseteq f^k(x) = x$
可知的确$f^{Fix}$是最小不动点。
通过上面的证明,我们又回答了一个问题:如果我们的迭代算法符合不动点定理的要求,那么迭代得到的不动点,确实就是最优不动点。
Relate Iterative Algorithm to Fixed Point Theorem 迭代算法与不动点定理的关系
以上我们只是定性的描述了是否能得到最优不动点,但是迭代算法怎样才能算是符合了不动点定理的要求呢?接下来介绍关联的方法。
首先,回想 fact 的形式:$(v_1^1,v_2^1,…,v_k^1)$,可以将其视为一个有限 lattice,它的积也是有限 lattice,因此 fact 对应到 finite lattice 是可以的。
然后,我们的迭代函数 F 包括了转移函数 f 和 join/meet 函数,证明 F 是单调的,那么也就能得到 $F: L\rightarrow L$ 是单调的。
这里分两部分。
- 转移函数,即 OUT = gen U (IN - kill),显然是单调的。
- 那么 join/meet 函数,我们要证明其单调,就是要证明:$\forall x,y,z\in L, x\sqsubseteq y$,有$x \sqcup z \sqsubseteq y \sqcup z$。
- 由定义,$y \sqsubseteq y \sqcup z$
- 由传递性,$x \sqsubseteq y \sqcup z$
- 则 $y \sqcup z$ 是 $x, z$ 的 ub
- 又 $x \sqcup z$ 是 $x, z$ 的 lub
- 因此 $x \sqcup z \sqsubseteq y \sqcup z$,证毕。
于是我们就完成了迭代算法到不动点定理的对应。
现在我们要回答本文开头的第三个问题了,什么时候算法停机?
这个问题就很简单了,因为每个 lattice 都有其高度。假设 lattice 的高度为 h,而我们的 CFG 节点数为 k,就算每次迭代可以使一个节点在 lattice 上升一个高度,那么最坏情况下,我们的迭代次数也就是 $i = h \times k$
最后我们再列出这三个问题与其回答:
- 算法是否确保一定能停止/达到不动点?能!会不会总是有一个解答?可以!
- 如果能到达不动点,那么是不是只有一个不动点?可以有很多。如果有多个不动点,我们的结果是最优的吗?是的!
- 什么时候我们会能得到不动点?最坏情况下,是 lattice 的高度与 CFG 的节点数的乘积。
May/Must Analysis, A Lattice View
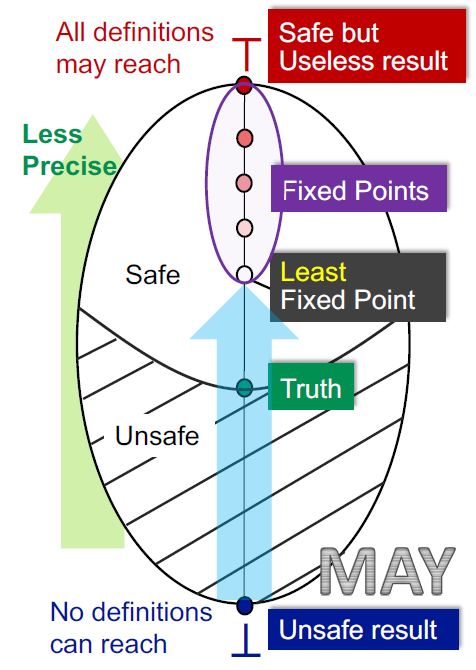
无论 may 还是 must 分析,都是从一个方向到另一个方向去走。考虑我们的 lattice 抽象成这样一个视图:
例如,对于到达定值分析,下界代表没有任何可到达的定值,上界代表所有定值都可到达。
下界代表 unsafe 的情形,即我们认为无到达定值,可对相关变量的存储空间进行替换。上界代表 safe but useless 的情绪,即认为定值必然到达,但是这对我们寻找一个可替换掉的存储空间毫无意义。
而因为我们采用了 join 函数,那么我们必然会从 lattice 的最小下界往上走。而越往上走,我们就会失去更多的精确值。那么,在所有不动点中我们寻找最小不动点,那么就能得到精确值最大的结果。
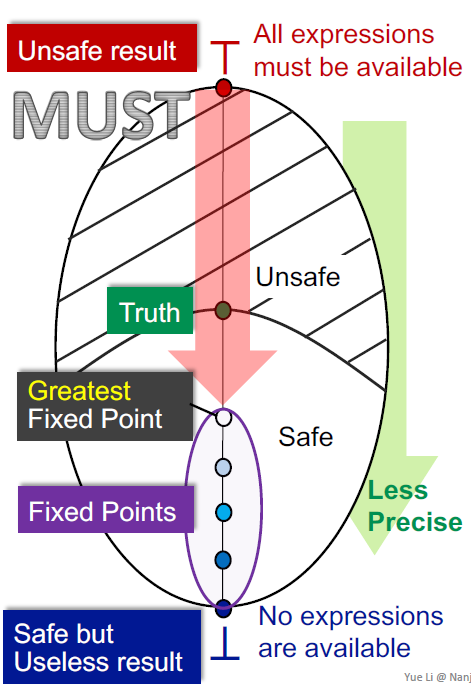
反之,在可用表达式分析中,下界代表无可用表达式,上界代表所有表达式都可用。
下界代表 safe but useless 的情形,因为需要重新计算每个表达式,即使确实有表达式可用。而上界代表 unsafe,因为不是所有路径都能使表达式都可用。与 may analysis 一样,通过寻找最大不动点,我们能得到合法的结果中精确值最大的结果。
Distributivity and MOP
我们引入 Meet-Over-All-Paths Solution(满足所有路径的解决方案),即 MOP。在这个 solution 中,我们不是根据节点与其前驱/后继节点的关系来迭代计算数据流,而是直接查找所有路径,根据所有路径的计算结果再取上/下界。这个结果是最理想的结果。
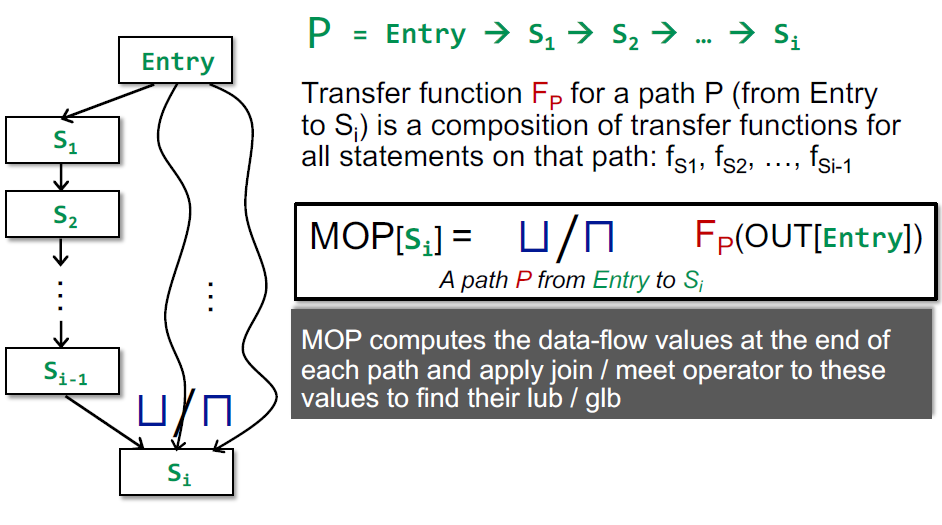
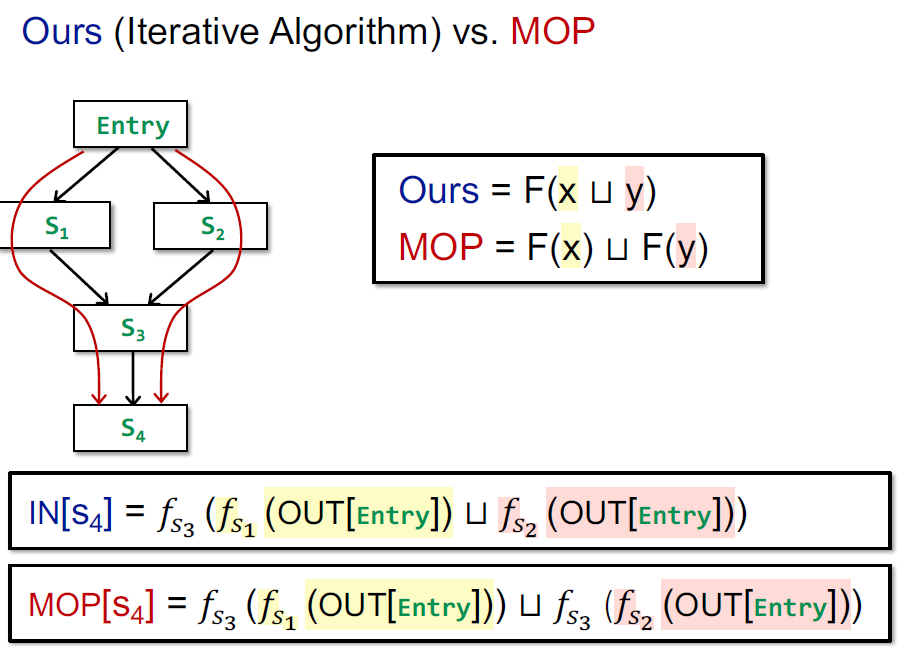
可以看到,迭代算法是 s3 对前驱取 join 后进行进行 f3 的转移,而 MOP 算法是对到达 s3 之后,s4 之前的路径结果取 join。
那么迭代算法和 MOP 哪个更精确呢?我们可以证明,$F(x)\sqcup F(y)\sqsubseteq F(x\sqcup y)$:

这表明 MOP 是更为精确的。
但这并没有结束。而如果 F 是可分配的,那么确实可以让偏序符号改为等于号。恰好,gen/kill problem 下,F 确实可分配因此我们能确定,迭代算法的精度与 MOP 相等。
Constant Propagation 常量传播
当然有些问题下 F 是不可分配的,如常量传播(Constant Propagation)。
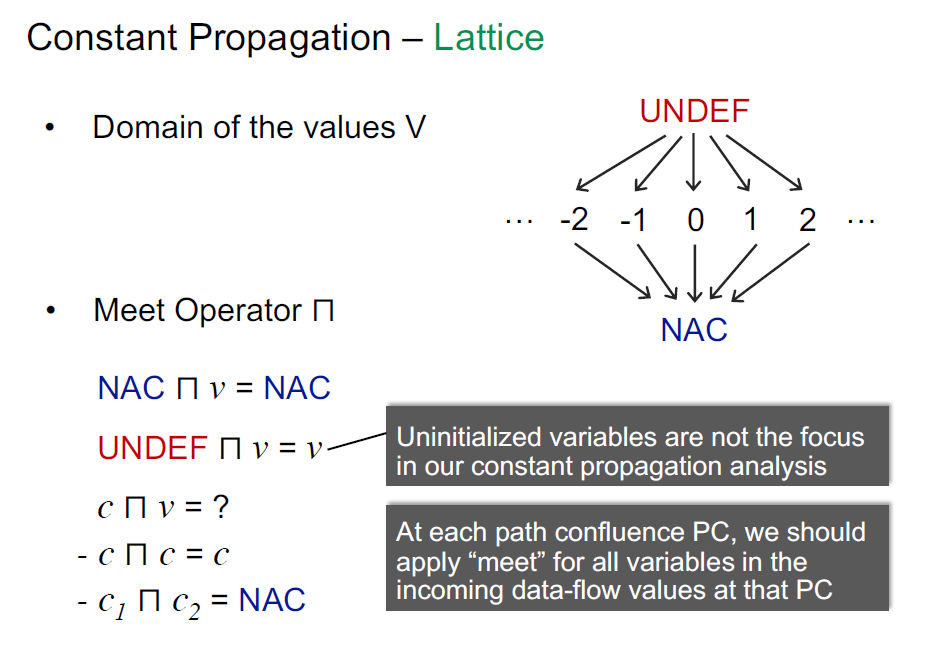
在常量传播分析中,其最大上界是 undefine,因为我们不知道一个变量到底被定义为了什么值。最小下界是 NAC(Not A Constant),而中间就是各种常量。这是因为分析一个变量指向的值是否为常量,那么要么它是同一个值,要么它不是常量。
给定一个 statement s: x = …,我们定义转移函数$OUT[s]=gen\cup(IN[s]-{(x,_)})$。
其中我们根据赋值号右边的不同,决定不同的 gen 函数:

注意,const + undef -> undef。因为 undef 变成 const 的过程中是降级,而如果 const1 + undef -> const2,那么 undef 变化为 const 时,const2 会发生改变,原来的 const2 与现在的 const2 不具有偏序关系,那么就不满足偏序关系的单调性了。
常量传播是不可分配的。以下图为例:
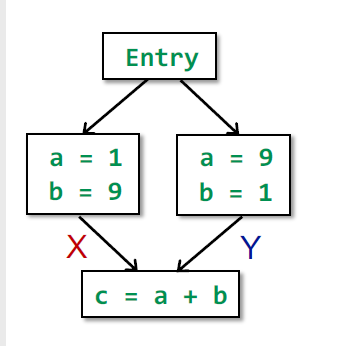
对于 c,$F(X)\sqcap F(Y) = 10, F(X\sqcap Y) = \text{NAC}$
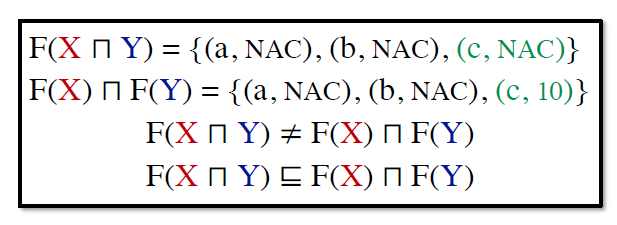
Worklist Algorithm 工作列表算法
worklist 是迭代算法的优化。

在 Worklist 算法中,只在基本块的 fact 发生变化处理其相关基本块,不必再在每次有 fact 变化时处理所有的基本块了。
评论
使用 GitHub 账号留言,讨论将同步为仓库 Issues。