Data Flow Analysis
Overview of Data Flow Analysis
数据流分析的核心:How Data Flows on CFG?
将这句话展开来,所谓数据流分析就是:
How application-specific Data (对数据的抽象:+, -, 0 等……) Flows (根据分析的类型,做出合适的估算) through the Nodes (数据如何 transfer, 如 + op + = +) and Edges (控制流如何处理,例如两个控制流汇入一个BB) of CFG (整个程序) ?
不同的数据流分析,有着不同的data abstraction, flow safe-approximation(流动安全近似值)策略,transfer functions&control-flow handlings(转移函数和控制流处理)。
在这里就能明白数据流中的Node、Edge代表的含义,比例CodeQL中就用了这个Node,Edge含义。
Preliminaries of Data Flow Analysis
Input and Output States 输入输出状态
- 每一条IR的执行,都会使状态从输入状态变成新的输出状态
- 输入/输出状态与语句前/后的 program point 相关联。
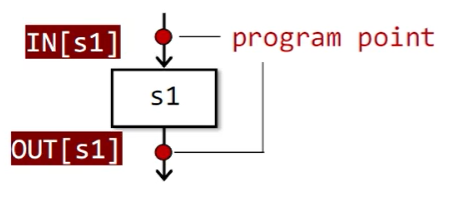
在数据流分析中,我们会把每一个PP关联一个数据流值,代表在该点中可观察到的抽象的程序状态。
关于转移方程约束的概念
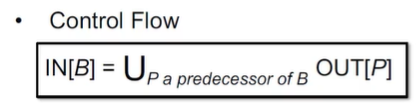
分析数据流有前向和后向两种:

关于控制流约束的概念
每条语句 s 都会使程序状态发生改变。
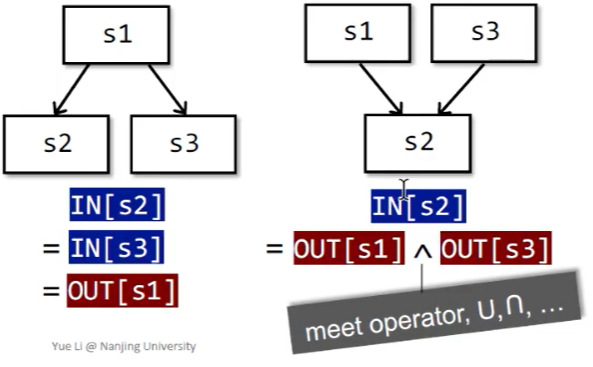
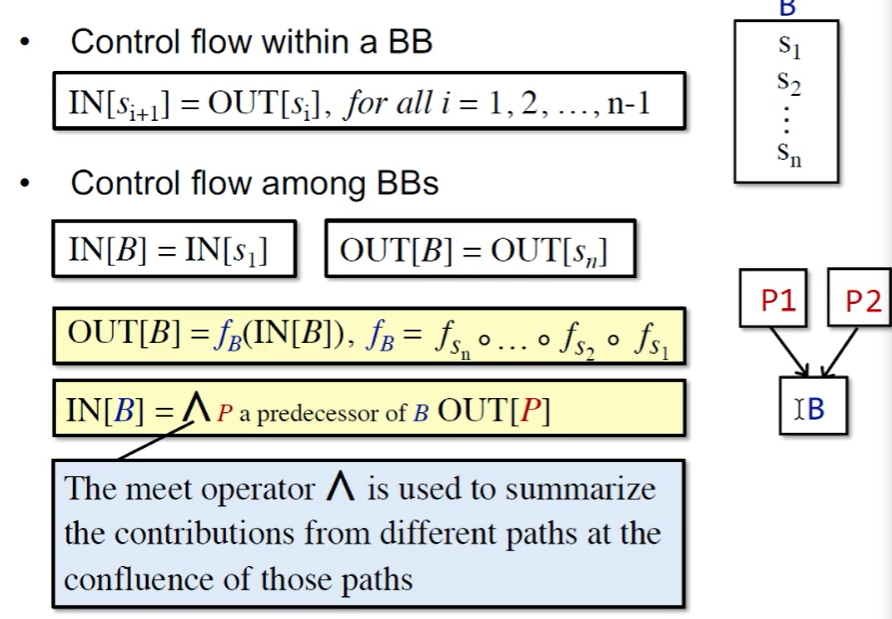
B 的输出自然是其输入在经过多次转换后得到的状态。
而 B 的输入要根据数据流分析的需求,对其前驱应用合适的 meet operator 进行处理。后向分析时亦然。
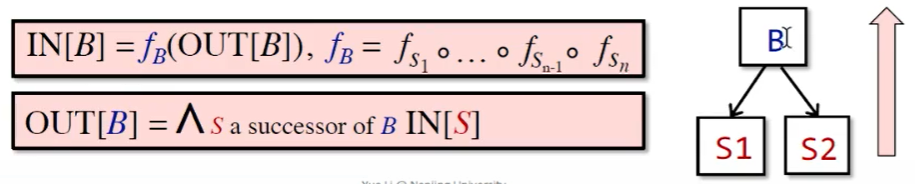
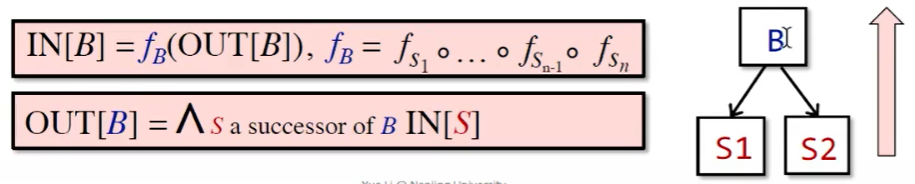
不会涉及到的概念
**>>>Hint**
* 函数调用 Method Calls * 我们将分析的是过程本身中的事情,即 Intra-procedural。而过程之间的分析,将在 Inter-procedural Analysis 中介绍</br> * 变量别名 Aliases</br> * 变量不能有别名。有关问题将在指针分析中介绍。</br>Reaching Definitions Analysis 到达定值分析
基本概念
- 假定 x 有定值 d (definition),如果存在一个路径,从紧随 d 的点到达某点 p,并且此路径上面没有 x 的其他定值点,则称 x 的定值 d 到达 (reaching) p。
- 如果在这条路径上有对 x 的其它定值,我们说变量 x 的这个定值 d 被杀死 (killed) 了
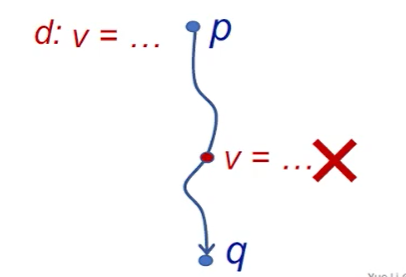
到达定值可以用来分析未定义的变量。例如,我们在程序入口为各变量引入一个 dummy (假的)定值。当程序出口的某变量定值依然为 dummy,则我们可以认为该变量未被定义。
对于一条赋值语句 D: v = x op y,该语句生成了 v 的一个定值 D,并杀死程序中其它对变量 v 定义的定值。
到达定值中的数据流值
-
程序中所有变量的定值。
-
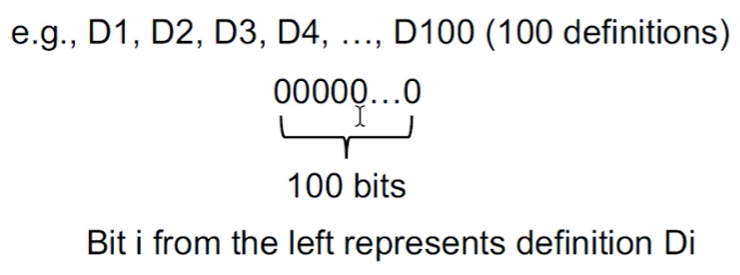
可以用一个 bit vector 来定义,有多少个赋值语句,就有多少个位。
到达定值的转移方程
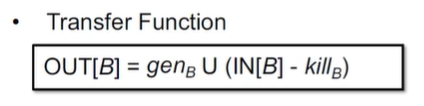
- 从入口状态删除 kill 掉的定值,并加入新生成的定值。
v = x op y,gen v, kill 其它所有的 v
到达定值的数据流处理
- 任何一个前驱的变量定值都表明,该变量得到了定义。
到达定值的算法

这是一个经典的迭代算法。
- 首先让所有BB和入口的OUT为空。因为你不知道 BB 中有哪些定值被生成。
- 当任意 OUT 发生变化,则分析出的定值可能需要继续往下流动,所需要修改各 BB 的 IN 和 OUT。
- 先处理 IN,然后再根据转移完成更新 OUT。
- 在 gen U (IN - kill) 中,kill 与 gen 相关的 bit 不会因为 IN 的改变而发生改变,而其它 bit 又是通过对前驱 OUT 取并得到的,因此其它 bit 不会发生 0 -> 1 的情况。所以,OUT 是不断增长的,而且有上界,因此算法最后必然会停止。
- 因为 OUT 没有变化,不会导致任何的 IN 发生变化,因此 OUT 不变可以作为终止条件。我们称之为程序到达了不动点(Fixed Point)
Live Variables Analysis 活跃变量分析
基本概念
- 变量 x 在程序点 p 上的值是否会在某条从 p 出发的路径中使用
- 变量 x 在 p 上活跃,当 且仅存在一条从 p 开始的路径,该路径的末端使用了 x,且路径上没有对 x进行覆盖。
- 隐藏了这样一个含义:在被使用前,v 没有被重新定义过,即没有被 kill 过。
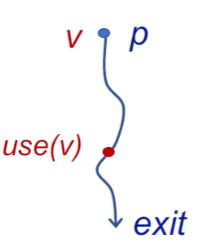
这个算法可以用于寄存器分配,当一个变量不会再被使用,那么此变量就可以从寄存器中腾空,用于新值的存储。
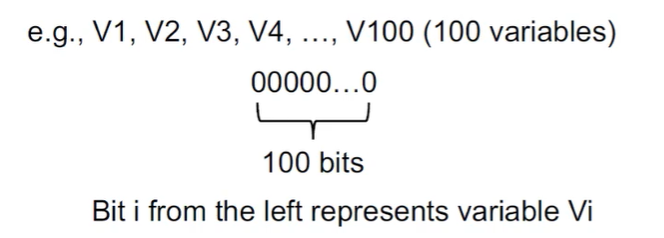
活跃变量中的数据流值
- 程序中的所有变量
- 依然可以用 bit vector 来表示,每个 bit 代表一个变量
活跃变量的转移方程和控制流处理
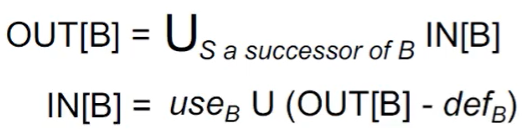
- 一个基本块内,若 v = exp, 则 def v。若 exp = exp op v,那么 use v。一个变量要么是 use,要么是 def,根据 def 和 use 的先后顺序来决定。
- 考虑基本块 B 及其后继 S。若 S 中,变量 v 被使用,那么我们就把 v 放到 S 的 IN 中,交给 B 来分析。
- 因此对于活跃变量分析,其控制流处理是 OUT[B] = IN[S]。
- 在一个块中,若变量 v 被使用,那么我们需要添加到我们的 IN 里。而如果 v 被定义,那么在其之上的语句中,v 都是一个非活跃变量,因为没有语句再需要使用它。
- 因此对于转移方程,IN 是从 OUT 中删去重新定值的变量,然后并上使用过的变量。需要注意,如果同一个块中,变量 v 的 def 先于 use ,那么实际上效果和没有 use 是一样的。
活跃变量的算法

- 我们不知道块中有哪些活跃变量,而且我们的目标是知道在一个块开始时哪些变量活跃,因此把 IN 初始化为空。
- 初始化的判断技巧:may analysis 是空,must analysis 是 top。
Available Expression Analysis 可用表达式分析
基本概念
- x + y 在 p 点可用的条件:从流图入口结点到达 p 的每条路径都对 x + y 求了值,且在最后一次求值之后再没有对 x 或 y 赋值
可用表达式可以用于全局公共子表达式的计算。也就是说,如果一个表达式上次计算的值到这次仍然可用,我们就能直接利用其中值,而不用进行再次的计算。
可用表达式分析中的数据流值
-
程序中的所有表达式
-
bit vector 中,一个 bit 就是一个表达式
可用表达式的转移方程和控制流处理
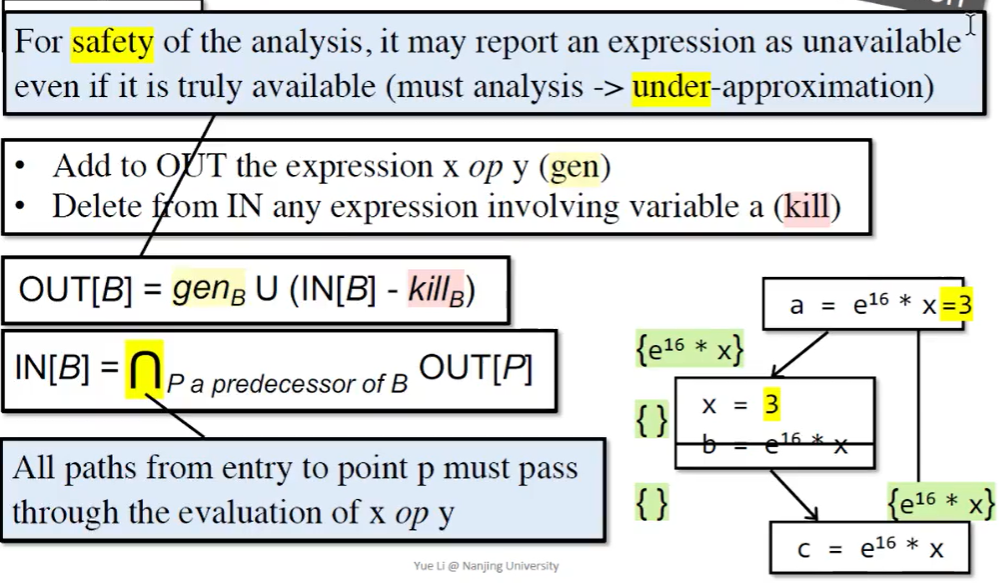
- 我们要求无论从哪条路径到达 B,表达式都应该已经计算,才能将其视为可用表达式,因此这是一个 must analysis。
- 注意到图中,两条不同的路径可能会导致表达式的结果最终不一致。但是我们只关心它的值能不能够再被重复利用,因此可以认为表达式可用。
- v = x op y,则 gen x op y。当 x = a op b,则任何包含 x 的表达式都被 kill 掉。若 gen 和 kill 同时存在,那么以最后一个操作为准。
- 转移方程很好理解,和到达定值差不多。但是,由于我们是 must analysis,因此控制流处理是取交集,而非到达定值那样取并集。
可用表达式的算法

- 注意此时的初始化:一开始确实无任何表达式可用,因此OUT[entry]被初始化为空集是自然的。但是,其它基本块的 OUT 被初始化为全集,这是因为当 CFG 存在环时,一个空的初始化值,会让取交集阶段直接把第一次迭代的 IN 设置成 0,无法进行正确的判定了。
- 如果一个表达式从来都不可用,那么OUT[entry]的全 0 值会通过交操作将其置为 0,因此不用担心初始化为全 1 会否导致算法不正确。
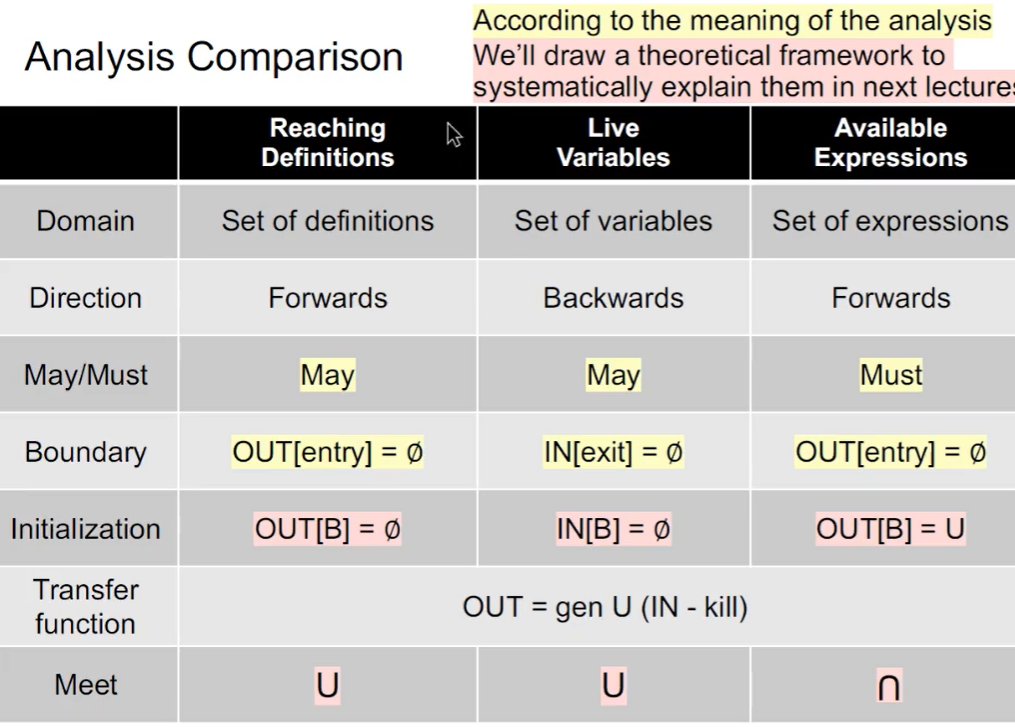
总结
评论
使用 GitHub 账号留言,讨论将同步为仓库 Issues。